
Integration of scRNA-seq#
During the analysis of scRNA-seq data, we normally have several samples.The main challenge that arises when dealing with multiple samples are the batch effects. Batch effects are changes in measured expression levels which can arise due to different reasons. Removing these effects is crucial to allow the joint analysis focussing on finding common structure in the data. In order to remove these batch effects, there are different type of methods, each one solving the issue using specific approaches.
In the DoTools, we included common integration methods used in sc/snRNA-seq data analysis, including: CCA (Seurat) and Harmony which perform well for simple batch correction tasks and scVI, scANVI and Scanorama, which perform well in more complex data integration tasks.
import matplotlib.pyplot as plt
!wget "https://ndownloader.figshare.com/files/52854605" -O /Users/david/Downloads/adata.h5ad
/Users/david/Downlo 100%[===================>] 3.28G 12.0MB/s in 3m 49s
2026-01-20 12:47:30 (14.6 MB/s) - ‘/Users/david/Downloads/adata.h5ad’ saved [3516946145/3516946145]
# Set Up
import dotools_py as do
import scanpy as sc
import session_info
adata = do.io.read_h5ad("/Users/david/Downloads/adata.h5ad") # Contains two different datasets
adata.X = adata.layers["logcounts"].copy()
adata
2026-01-21 15:38:30,311 - Jupyter enviroment detected. Using "inline" backend
AnnData object with n_obs × n_vars = 64845 × 25425
obs: 'sample', 'condition', 'Experiment', 'leiden1_5', 'autoAnnot', 'annotation', 'leiden5', 'n_genes_by_counts', 'log1p_n_genes_by_counts', 'total_counts', 'log1p_total_counts', 'total_counts_mt', 'log1p_total_counts_mt', 'pct_counts_mt', 'total_counts_ribo', 'log1p_total_counts_ribo', 'pct_counts_ribo', 'batch', 'age'
var: 'GeneSymbol', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mt', 'ribo', 'n_cells_by_counts', 'mean_counts', 'log1p_mean_counts', 'pct_dropout_by_counts', 'total_counts', 'log1p_total_counts'
uns: 'age_colors', 'annotation_colors', 'autoAnnot_colors', 'batch_colors', 'condition_colors', 'hvg', 'leiden1_5', 'leiden1_5_colors', 'leiden5', 'leiden5_colors', 'neighbors', 'pca', 'sample_colors', 'umap'
obsm: 'X_scVI', 'X_umap'
varm: 'PCs'
layers: 'counts', 'logcounts'
obsp: 'connectivities', 'distances'
To perform data integration, we first compute the highly variable genes. This allows both to improve the biological signal recovery and computational performance. This is important, because most of the genes in scRNA-seq are lowly expressed, uninformative across cells or dominated by technical noise.
sc.pp.highly_variable_genes(adata, batch_key='batch') # Detect HVGs shared across samples
adata.var["highly_variable"].value_counts()
extracting highly variable genes
finished (0:00:02)
--> added
'highly_variable', boolean vector (adata.var)
'means', float vector (adata.var)
'dispersions', float vector (adata.var)
'dispersions_norm', float vector (adata.var)
highly_variable
False 21748
True 3677
Name: count, dtype: int64
As we can observe, we will use 3,677 highly variable genes instead of the 22,536 genes that we have in our object. After the selection of HVGs we can proceed with the integration.
Unintegrated#
We first will compute the UMAP embeddings without performing integration using PCA.
adata_unintegrated = adata.copy()
sc.pp.pca(adata_unintegrated)
do.tl.integrate_data(adata_unintegrated, batch_key="batch", hvg_batch=True, integration_method="pca")
do.pl.split_embeddding(adata_unintegrated, "batch", ncols=5)
computing PCA
with n_comps=50
finished (0:00:03)
2026-01-21 15:38:40,526 - Computing HVGs
extracting highly variable genes
finished (0:00:01)
--> added
'highly_variable', boolean vector (adata.var)
'means', float vector (adata.var)
'dispersions', float vector (adata.var)
'dispersions_norm', float vector (adata.var)
computing PCA
with n_comps=50
finished (0:00:11)
2026-01-21 15:38:55,845 - Finding neighbors
computing neighbors
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:11)
2026-01-21 15:39:07,543 - Run UMAP
computing UMAP
finished: added
'X_umap', UMAP coordinates (adata.obsm)
'umap', UMAP parameters (adata.uns) (0:00:22)
2026-01-21 15:39:30,054 - Clustering cells using Leiden (resolution 0.3)
running Leiden clustering
finished: found 19 clusters and added
'leiden', the cluster labels (adata.obs, categorical) (0:00:00)
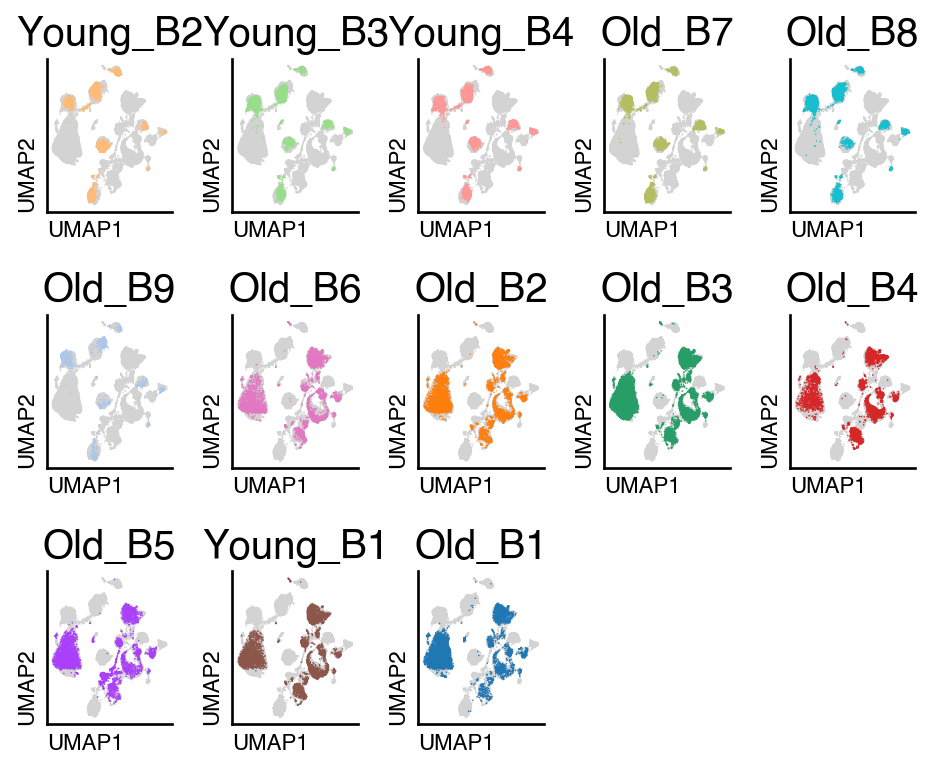
Harmony#
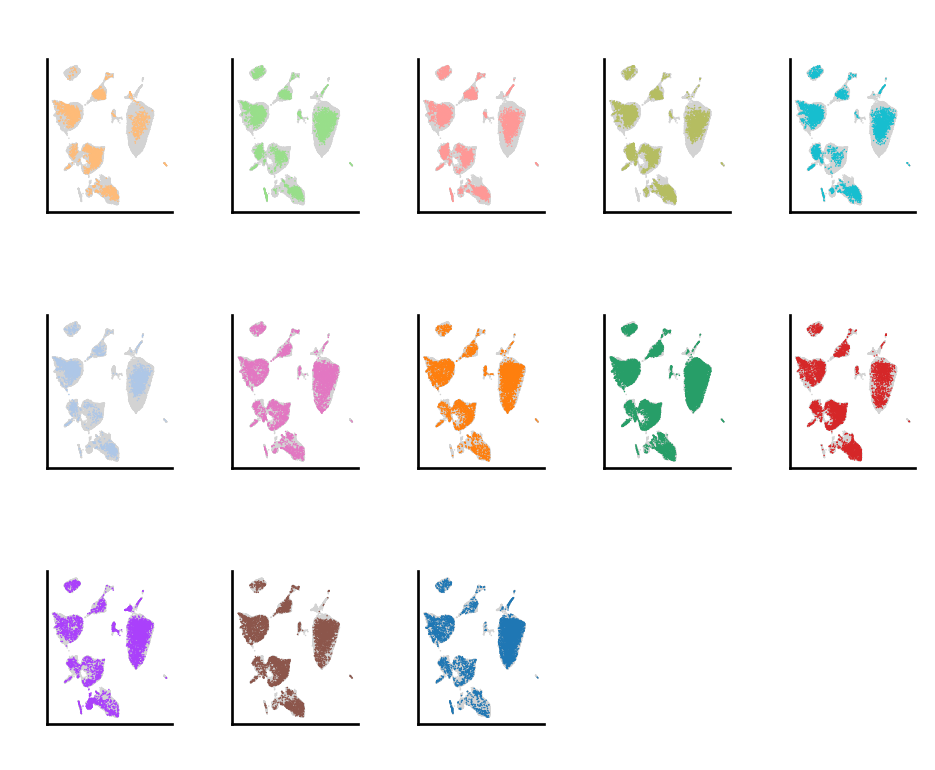
In this method, after performing the selection of HVGs, we perform dimensionality reduction, like Principal Component Analysis (PCA). Harmony performs integration by adjusting cell embeddings (typically PCA components) so that cells from different batches align while preserving underlying biological structure. The quality of these embeddings depends heavily on which genes are used to generate them.
adata_harmony = adata.copy()
do.tl.integrate_data(adata_harmony, batch_key="batch", hvg_batch=True, integration_method="harmony")
do.pl.split_embeddding(adata_harmony, "batch", ncols=5)
adata_harmony.obsm.keys()
KeysView(AxisArrays with keys: X_scVI, X_umap, X_harmony)
After performing integration with Harmony, we have a new representation in adata.obsm called X_harmony, which contains the batch corrected representation of the data. To perform re-clustering, there are two different approaches: use this representation to find the closest cell neighbors, or re-compute the batch corrected embedding after selecting the cell type or cluster of interest.
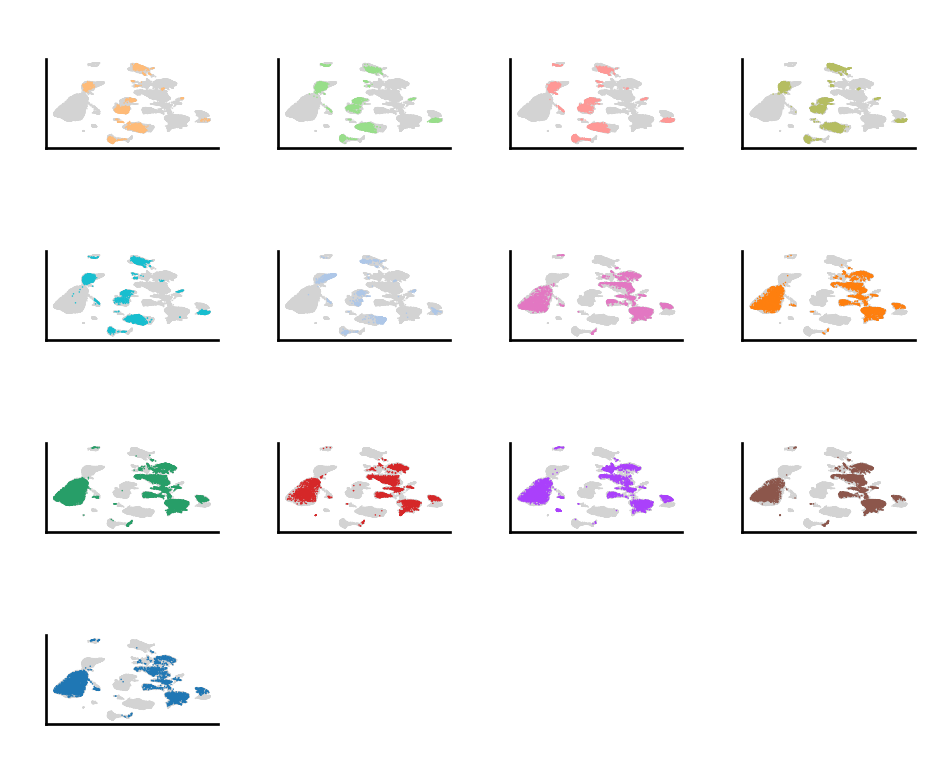
Scanorama#
In this method, integration of single-cell datasets is performed by matching biologically similar cells across batches and then computing a non-linear correction that aligns the datasets into a shared low-dimensional space. The core idea is panoramic stitching: identify overlaps between datasets and merge them pairwise, propagating the alignment globally.
adata_scanorama = adata.copy()
do.tl.integrate_data(adata_scanorama, batch_key="batch", hvg_batch=True, integration_method="scanorama")
do.pl.split_embeddding(adata_scanorama, "batch", ncols=5)
adata_scanorama.obsm.keys()
KeysView(AxisArrays with keys: X_scVI, X_umap, X_scanorama)
After performing integration with Scanorama, we have a new representation in adata.obsm called X_scanorama, which contains the batch corrected representation of the data. To perform re-clustering, there are two different approaches: use this representation to find the closest cell neighbors, or re-compute the batch corrected embedding after selecting the cell type or cluster of interest. In our case, we use the second approach in dotools_py.tl.reclustering.
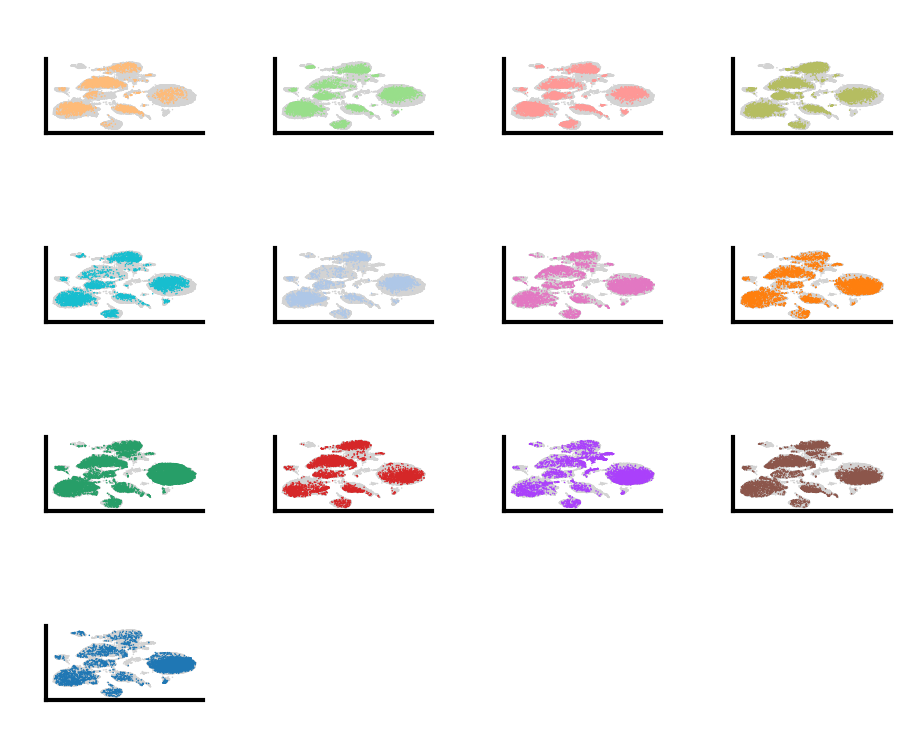
Seurat CCA#
The canonical correlation analysis (CCA) is designed to correct batch effects and align shared biological structure across multiple single-cell datasets while preserving meaningful biological variation. CCA is applied to pairs of datasets to find linear combinations of genes (canonical vectors) that are maximally correlated between datasets. These canonical components represent shared sources of biological variation across batches. Using the CCA space, Seurat identifies anchors—pairs of cells from different datasets that are mutual nearest neighbors in the shared low-dimensional space. Anchors serve as correspondences between datasets and encode how datasets should be aligned. Anchors are then filtered to remove weak or ambiguous matches and are weighted based on similarity. This improves robustness and prevents overcorrection.
Between Seurat v4 and v5 there was a change on how it is performed. In version 4, dimensionality reduction was performed after generated a CCA embedding but in version 5, dimensionality reduction is performed before. This help reducing the computation time, we will use v5 to speed up the analysis.
adata_cca5 = adata.copy()
do.tl.integrate_data(adata_cca5, batch_key="batch", hvg_batch=True, integration_method="cca5")
do.pl.split_embeddding(adata_cca5, "batch")

scVI#
The method scVI (single-cell Variational Inference) is a deep generative modeling framework for single-cell RNA-seq data that performs batch correction and integration by learning a shared latent representation of cells. It models gene expression counts using a hierarchical variational autoencoder, typically assuming a negative binomial (or zero-inflated negative binomial) likelihood, while explicitly conditioning on batch and other covariates. During training, scVI separates biological variation from technical effects by encoding cells into a low-dimensional latent space that is invariant to batch, while batch information is modeled in the decoder. The learned latent space can be used for visualization, clustering, and trajectory analysis, and the model enables downstream tasks such as differential expression through probabilistic inference on the original count scale. scVI is particularly effective for large, complex datasets with strong batch effects and does not require explicit feature selection, making it a flexible and scalable integration method.
adata_scvi = adata.copy()
do.tl.integrate_data(adata_scvi, batch_key="batch", hvg_batch=True, integration_method="scvi", categorical_covariates=["Experiment"], continuous_covariates=["total_counts"])
do.pl.split_embeddding(adata_scvi, "batch")
Integration Comparison#
We can now also compare how well the integration methods work for this dataset using the dotools_py.bm, we will compute different metrics. The values are scaled between 0 and 1 with larger values indicating a better conservation of biological information.
adata_combined = adata.copy()
adata_combined.obsm["X_CCA"] = adata_cca5.obsm["X_CCA"]
adata_combined.obsm["X_harmony"] = adata_harmony.obsm["X_harmony"]
adata_combined.obsm["X_scVI"] = adata_scvi.obsm["X_scVI"]
adata_combined.obsm["X_scanorama"] = adata_scanorama.obsm["X_scanorama"]
adata_combined.write("/Users/david/Downloads/adata_combined.h5ad")
table = do.bm.eval_integration(
adata_post=adata_combined,
adata_pre=adata_unintegrated,
batch_key="batch",
annotation_key="annotation",
use_rep=["X_CCA","X_harmony", "X_scVI", "X_scanorama"],
palette={"X_CCA":"royalblue", "X_harmony":"firebrick", "X_scVI":"forestgreen", "X_scanorama":"moccasin"}
)
2026-01-21 15:39:34,259 - Computing metrics for X_CCA
computing PCA
with n_comps=50
finished (0:00:00)
2026-01-21 15:43:47,831 - Computing metrics for X_harmony
computing PCA
with n_comps=50
finished (0:00:00)
2026-01-21 15:48:00,336 - Computing metrics for X_scVI
computing PCA
with n_comps=30
finished (0:00:00)
2026-01-21 15:52:15,217 - Computing metrics for X_scanorama
computing PCA
with n_comps=50
finished (0:00:00)
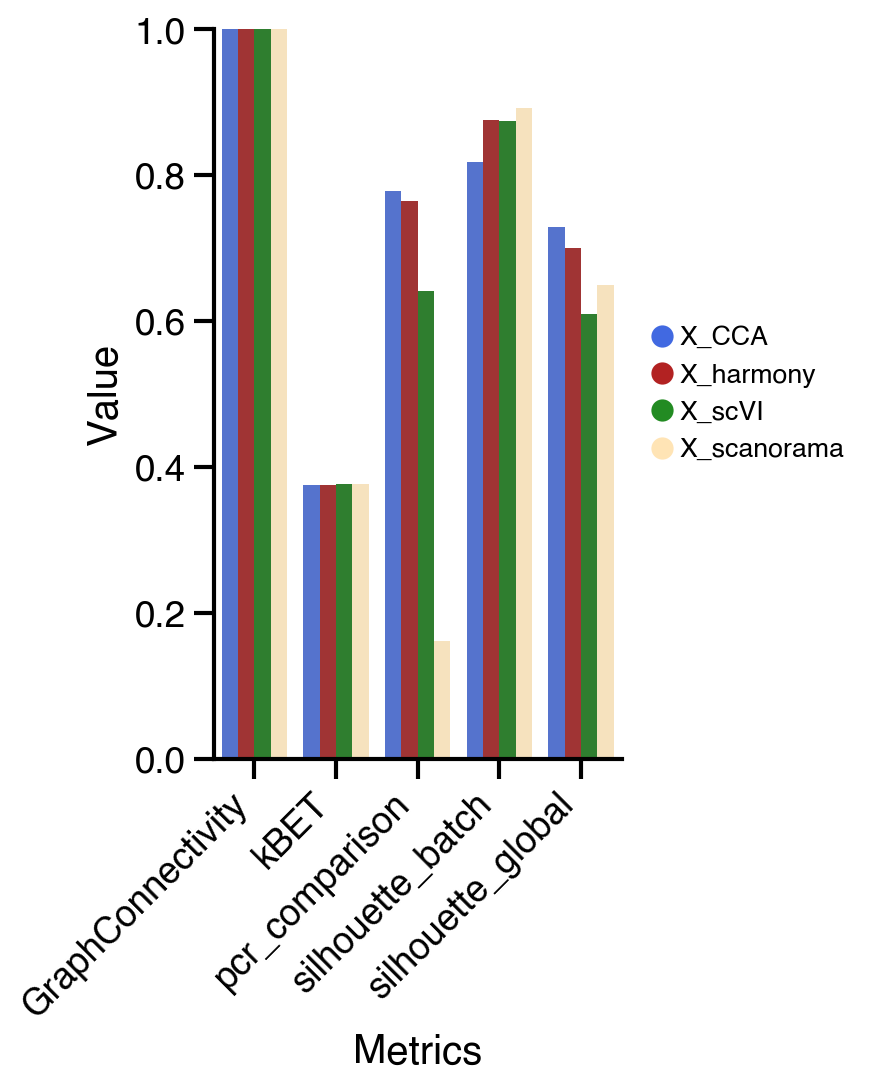
We can observe differences across the different metrics. For example the PCR comparison, which compare the explained variance before and after the integration, shows the highest change for X_CCA. On the other hand, the average silhouette for the batches shows better results for X_scVI and X_harmony.
In general, we can see similar results in this dataset for the different methods. If we inspect the UMAPs we can observed that X_scVI, X_CCA, and X_harmony behave similarly good. Selection of the optimal integration method normally will depend on the nature of the dataset and the computational resources available. For instance, Seurat CCA integration method might be slower compared to other methods depending on the machine it is run. scVI allows to include categorical and continuous covariate to correct for technical artifacts and would be suitable for more complex experiments. Additionally, to decrease the run time it allows the use of GPU if available. Therefore, when suboptimal results are observed is recomended to try other integration methods.
session_info.show(na=False, cpu=True, excludes=["backports"], std_lib=True, dependencies=True, html=True)
Click to view session information
----- anndata 0.11.4 dotools_py 0.0.1 pandas 2.3.2 platform 1.0.8 psutil 7.1.0 scanpy 1.11.4 session_info v1.0.1 -----
Click to view modules imported as dependencies
Cython 3.1.4 PIL 11.3.0 absl 2.3.1 adjustText 1.3.0 appnope 0.1.4 argparse 1.1 arrow 1.3.0 attr 25.3.0 attrs 25.3.0 babel 2.17.0 beartype 0.22.8 certifi 2025.08.03 cffi 2.0.0 charset_normalizer 3.4.3 chex 0.1.91 cloudpickle 3.1.1 comm 0.2.3 coverage 7.11.0 csv 1.0 ctypes 1.1.0 cycler 0.12.1 cython 3.1.4 dask 2024.11.2 dateutil 2.9.0.post0 debugpy 1.8.17 decimal 1.70 decorator 5.2.1 defusedxml 0.7.1 deprecated 1.2.18 docrep 0.3.2 etils 1.13.0 executing 2.2.1 filelock 3.19.1 flax 0.12.0 fsspec 2025.9.0 funsor 0.4.5 geopandas 1.1.1 h5py 3.14.0 idna 3.10 igraph 0.11.9 ipaddress 1.0 ipykernel 6.30.1 ipywidgets 8.1.7 jax 0.8.0 jaxlib 0.8.0 jedi 0.19.2 jinja2 3.1.6 joblib 1.5.2 json 2.0.9 json5 0.12.1 jsonpointer 3.0.0 jsonschema 4.25.1 jupyter_events 0.12.0 jupyter_server 2.17.0 jupyterlab_server 2.27.3 kiwisolver 1.4.9 lark 1.2.2 leidenalg 0.10.2 lightning 2.5.5 lightning_utilities 0.15.2 llvmlite 0.45.0 logging 0.5.1.2 makefun 1.16.0 markupsafe 3.0.2 marshal 4 matplotlib 3.10.6 matplotlib_inline 0.1.7 ml_collections 1.1.0 ml_dtypes 0.5.3 mpmath 1.3.0 msgpack 1.1.2 mudata 0.3.2 multipledispatch 0.6.0 natsort 8.4.0 nbformat 5.10.4 numba 0.62.0 numcodecs 0.15.1 numpy 2.3.3 numpyro 0.19.0 opt_einsum 3.4.0 optax 0.2.6 packaging 25.0 parso 0.8.5 patsy 1.0.1 platformdirs 4.4.0 polars 1.33.1 prompt_toolkit 3.0.52 pure_eval 0.2.3 pyarrow 21.0.0 pycparser 2.23 pydot 4.0.1 pygments 2.19.2 pynndescent 0.5.13 pyparsing 3.2.4 pyproj 3.7.2 pyro 1.9.1 pytz 2025.2 re 2.2.1 requests 2.32.5 rfc3339_validator 0.1.4 rfc3986_validator 0.1.1 scib 1.1.7 scipy 1.15.3 scvi 1.4.0 seaborn 0.13.2 shapely 2.1.2 simplejson 3.20.2 six 1.17.0 sklearn 1.7.2 sniffio 1.3.1 socketserver 0.4 sparse 0.17.0 sqlite3 2.6.0 stack_data 0.6.3 statsmodels 0.14.5 stdlib_list 0.11.1 sympy 1.14.0 sys 3.11.13 (main, Jun 5 2025, 08:21:08) [Clang 14.0.6 ] tarfile 0.9.0 texttable 1.7.0 threadpoolctl 3.6.0 tlz 1.0.0 toolz 1.0.0 torch 2.8.0 torchmetrics 1.8.2 tornado 6.5.2 tqdm 4.67.1 traitlets 5.14.3 umap 0.5.9.post2 urllib3 2.5.0 wcwidth 0.2.13 websocket 1.8.0 wrapt 1.17.3 xarray 2025.9.0 yaml 6.0.2 zarr 2.18.7 zlib 1.0 zmq 27.1.0
----- IPython 9.5.0 jupyter_client 8.6.3 jupyter_core 5.8.1 jupyterlab 4.4.7 notebook 7.4.5 ----- Python 3.11.13 (main, Jun 5 2025, 08:21:08) [Clang 14.0.6 ] macOS-26.2-arm64-arm-64bit 10 logical CPU cores, arm ----- Session information updated at 2026-01-20 21:10
import platform
import psutil
print("OS:", platform.platform())
print("Machine:", platform.machine())
print("Processor:", platform.processor())
print("CPU cores (physical):", psutil.cpu_count(logical=False))
print("CPU cores (logical):", psutil.cpu_count(logical=True))
print("Total RAM (GB):", round(psutil.virtual_memory().total / (1024 ** 3), 2))
print("Python version:", platform.python_version())
OS: macOS-26.2-arm64-arm-64bit
Machine: arm64
Processor: arm
CPU cores (physical): 10
CPU cores (logical): 10
Total RAM (GB): 16.0
Python version: 3.11.13